Partitioned outer join
Jaromir D.B. Nemec
I first read about this feature from Jonathan Gennicks newslewtter.
The syntax used there was a "beta version"; instead of ANSI approved
"PARTITION BY" a "WITHIN GROUP" clause was used. But on the
first view it was clear: this is a great "gap filling" feature.
Let prepare a very simplified test table to demonstrate this feature. A
classical example to demonstrate this feature is a sales table with a few
dimension around it.
SQL> create table sales
2 (prod_id number,
3 time_id number,
4 customer_id number,
5 amount_sold number);
Table created.
The sales table is a fact table containing the measures - in our case
only amount_sold - related to the dimensions: product, time and customer. The full
script to create the environment can be found here. The
dimensions are based on surrogate keys and - to keep it simple - have no other attributes.
This is not very realistic example, but for our demonstration there is no need
to know what exact date or other attributes corresponds to e.g. time_id = 1.
The dimension space looks as follows:
|
Time |
1 |
2 |
3 |
4 |
5 |
|
Product |
1 |
2 |
3 |
|
|
|
Customer |
1 |
2 |
3 |
4 |
|
The total overview of the sales table:
SQL> select * from
sales
2
order by time_id, prod_id, customer_id;
PROD_ID
TIME_ID CUSTOMER_ID AMOUNT_SOLD
---------- ----------
----------- -----------
1 1 1 10
1 1 1 20
1
1 2 1
3 1 1 31
2 2 1 21
2 2 2 19
2 2 3 8
3 2 3 30
2 3 2 12
2 3 4 40
3 3 2 35
Sales Example
Let examine the sales summarised on the time dimension.
SQL> select time_id, sum(amount_sold) amount_sold
2 from sales
3 group by time_id
4 order by time_id;
TIME_ID
AMOUNT_SOLD
---------- -----------
1 62
2 78
3
87
We see there are no sales on time_id 4 and 5, so those time_id doesn't appear
in the report. An outer join can improve it.
SQL> select t.time_id, sum(nvl(amount_sold,0)) amount_sold
2 from times t, sales s
3 where t.time_id = s.time_id(+)
4 group by t.time_id
5 order by t.time_id;
TIME_ID
AMOUNT_SOLD
---------- -----------
1 62
2 78
3 87
4 0
5 0
Lets use the ANSI join syntax for the same query - this is necessary as
the partition outer join can be use only with the ANSI join syntax.
SQL> select t.time_id, nvl(amount_sold,0) amount_sold from
2 (select time_id, sum(amount_sold) amount_sold
3 from sales
4 group by time_id) s
5 right outer join times t
6 on (t.time_id = s.time_id)
7 order by t.time_id;
TIME_ID AMOUNT_SOLD
---------- -----------
1 62
2 78
3 87
4 0
5 0
This query returns the same result as the query above. Note the syntax
RIGHT OUTER JOIN, which means that the *right* table (i.e. the sales inline
view)
is preserved and the *left* table should be added with NULLs.
How to get a complete picture based on time and product dimensions? If
we simple add prod_id in the subquery the result contains all sales
transactions per product and time but it doesn't contain the full dimensional
picture (i.e. the combination of product and time dimension entries without
transaction doesn't appear).
SQL> select s.prod_id, t.time_id, nvl(amount_sold,0) amount_sold from
2 (select prod_id, time_id, sum(amount_sold) amount_sold
3 from sales
4 group by prod_id, time_id) s
5 right outer join times t
6 on (t.time_id = s.time_id)
7 order by s.prod_id, t.time_id;
PROD_ID TIME_ID AMOUNT_SOLD
---------- ---------- -----------
1 1 31
2 2 48
2 3 52
3 1 31
3 2 30
3 3 35
4 0
5 0
Note that for time_id = 1 there is no row with prod_id = 2, for time_id =
4 and 5 the prod_id is simple NULL!
With partitioned outer join we receive a full dimensional picture:
SQL> select
2
s.prod_id, t.time_id, nvl(amount_sold,0) amount_sold
3
from
4
(select prod_id, time_id, sum(amount_sold) amount_sold
5
from sales
6
group by prod_id, time_id) s
7
PARTITION BY (prod_id)
8
right outer join
9
times t on (t.time_id = s.time_id)
10
order by s.prod_id, t.time_id
11 ;
PROD_ID
TIME_ID AMOUNT_SOLD
---------- ----------
-----------
1 1 31
1 2 0
1
3 0
1 4 0
1 5 0
2 1 0
2 2 48
2 3 52
2 4 0
2 5 0
3 1 31
3 2 30
3 3 35
3 4 0
3 5 0
15 rows selected.
Note that there are exactly 15 rows selected - 5 time ID's times 3
product ID's.
How it works?
Conceptually the partitioned outer join can be explained in following
steps:
1) All distinct product ID from the sales inline view are investigated
(select distinct prod_id …)
2) A Cartesian product of the time dimension with the constructed
product dimension from step 1 is build
3) The build dimension is outer joined back to the sales inline view
(the join predicate is extended with the
partition expression, in our case with prod_id
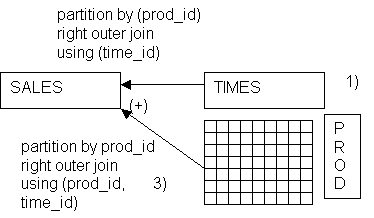
2)
Alternative Approach
From the definition above comes quick an idea of an alternative approach
to perform the same query.
Why to partition the sales table to get all prod_id's if there exists a
product dimension table?
The alternative query may be formulate as follows.
SQL> select
2
t.prod_id, t.time_id, nvl(amount_sold,0) amount_sold
3
from
4
(select prod_id, time_id, sum(amount_sold) amount_sold
5
from sales
6
group by prod_id, time_id) s
7
right outer join
8
(select time_id, prod_id from times, products) t -- cartesian product
9 on
(t.time_id = s.time_id and t.prod_id = s.prod_id)
10
order by t.prod_id, t.time_id
11 ;
PROD_ID
TIME_ID AMOUNT_SOLD
---------- ----------
-----------
1 1 31
1 2 0
1 3 0
1 4 0
1 5 0
2 1 0
2 2 48
2 3 52
2 4 0
2 5 0
3 1 31
3 2 30
3 3 35
3 4 0
3 5 0
15 rows selected.
Instead of examining the sales table digging for prod_id's, we build the
Cartesian join of time and product dimension on our own and outer join it to
the sales table.
There is one possible trap in this approach. If the product dimension
itself has "gaps" (i.e. in the sales table are references of
prod_id's without corresponding entry in the product dimension table) the
result will not be complete - the not defined product ID's will not appear.
Possible Traps
This following question should be - in my opinion - clear in advance as
a result of the general design of the application.
What kind of gaps ought to be filled?
a) products without a sales transaction on some point in time or
b) products that are not defined in the product dimension table
In both case the partitioned outer join can be used, in the letter case
the real strength of this kind of join can be exploited - but on the other side
this case
(i.e. violation of referential integrity) is often not a desired state in an application.
An other point to be considered while using partition outer join is a
constraint on the partitioned column. An extreme case (e.g. where prod_id = 1)
degenerates
the partitioned outer join to a simple outer join.
A care should be taken while joining to large fact tables with a
constraint on the time dimension. Lets illustrate it on an example with
restricted time dimension -
time_id in (2,3)
SQL> select
2
s.prod_id, t.time_id, nvl(amount_sold,0) amount_sold
3
from
4 (select prod_id,
time_id, sum(amount_sold) amount_sold
5
from sales
6
group by prod_id, time_id) s
7
PARTITION BY (prod_id)
8
right outer join
9
times t on (t.time_id = s.time_id)
10
where t.time_id in (2,3)
11
order by s.prod_id, t.time_id
12 ;
PROD_ID
TIME_ID AMOUNT_SOLD
---------- ----------
-----------
1 2 0
1 3 0
2 2 48
2 3 52
3 2 30
3 3 35
6 rows selected.
Notice that even though the last usage of the product prod_id = 1 was on
time_id = 1, we see this product in the report. The reason of this is, that the
whole sales table is scaned for distinct prod_id's - not only the part of the
sales table corresponding to the restriction of the time dimension (time_id in
(2,3)). This could lead to an "interesting" side effect of partitioned outer join. Let imagine you have a
wide fact table range partitioned on time containing say 10 years of data. While performing an partitioned outer join
with time dimension restricted to year 2004 don't wonder that all 10 year
partitions are scanned to get really *all* prod_id - possible obsolete product
appear in the report without usage. If this is not desired, an additional
explicit constraint of the sales table - identical with the restriction on the
time dimension (time_id in (2,3)) is required.
3 D Example
How to extend the partitioned outer join to get a report of three
dimensions (in our case time, product and customer)?
Simply recursive apply to the result set from query above an other
partitioned outer join using the new dimension (customer), partitioned on the
two dimensions of the first query (time, product).
An example with limited time dimension (time_id in (2,3)) see below.
SQL> select
a.prod_id,c.customer_id, a.time_id, nvl(amount_sold,0) amount_sold
2
from
3
(select
4
s.prod_id, t.time_id, s.customer_id, amount_sold
5
from (
6
select prod_id, time_id, customer_id, sum(amount_sold) amount_sold
7
from sales
8
where time_id in (2,3)
9
group by prod_id, time_id, customer_id) s
10
PARTITION BY (prod_id)
11
right outer join
12
times t on (t.time_id = s.time_id)
13
where t.time_id in (2,3)) a
14
PARTITION BY (prod_id, time_id)
15
right outer join
16
customers c on (a.customer_id = c.customer_id)
17 order
by a.prod_id,c.customer_id, a.time_id;
PROD_ID CUSTOMER_ID TIME_ID AMOUNT_SOLD
----------
----------- ---------- -----------
2 1 2 21
2 1 3 0
2 2 2 19
2 2 3 12
2 3 2 8
2 3 3 0
2 4 2 0
2 4 3 40
3 1 2 0
3 1 3 0
3 2 2 0
3 2 3 35
3 3 2 30
3 3 3 0
3 4 2 0
3 4 3 0
16 rows selected.
Note that the sales table was constrained with the same where clause as
time dimension to get rid of obsolete products.
Other Side of a Gap
I expect the main area of leveraging partitioned outer join to be the realm
of reporting tools on the very high end of aggregated data. I would be glad to
be wrong, but I don’t see at the moment an application of this feature to be a
"working horse" of ETL processing.
When I first heard a brief mention of a "gap filling join" in
very early 10g presentation I thought immediately on a theta-join (i.e. a non
equi-join let say with a join predicate a.x between b.y and b.z). This
"between" in a join predicate could be also interpreted as a
"gap" to be filled within a join. This kind of join is not uncommon
in some areas of ETL processing currently leading to not very optimal execution
plans.
But partitioned outer join is a complete different story. Let's wait
what the next gap filling feature will be…
Credits
The inspiration of some
aspects of this paper is credited to Christian
Antognini.
Further Reading
search Oracle 10g manuals for following terms
Read Tom
Kyte's article
or simple google
Jaromir D.B. Nemec
The author is a
freelancer specialized on Oracle based decision support systems. He can
be reached on http://www.db-nemec.com